
Interestingly, it would probably do a better job of writing a piece of code to count how many T’s there are, and then reading output of that.
Yeah, it’s pretty efficient at that. When the strawberry version was around, CGPT wrote some python and executed it after asking it programatically
I’ll never tire of LLM aneurysms.
This is why the steam deck is $1,000 btw
“Coloniatism” is my favourite

And this shit is “taking people’s jobs”
Hahahahahahahahahahahahahahahaha
Is this actually real though?
Just tested with similar results, output was:
There are exactly 2 't’s in the word ‘colonialism’. C-o-l-o-n-i-a-l-i-s-m Would you like to check the spelling or character count of any other words? Let me know!
Wow, I didn’t think it was still that stupid
I don’t think this particular genre of stupid will ever be fully fixed in LLMs to be honest, it’s fairly structural
I hope so
What causes this?
LLMs break words up into chunks of letters which commonly appear - suffixes like “-tion” and “-ism” are obvious examples. They then predict which chunk comes next based on the ones before, or whether the word will end.
This is very useful for generating sensible-looking text while at the same time correlating concepts associated with different words. However, it also means that the dont really “see” the letters that make up each word, just the chunks of letters, which are stored as mathematical vectors. This is why they struggle so much with analysing the makeup of words.
However, with numbers they generally store each digit individually, so they shouldnt have as much of a problem saying how many 5’s are in 1,589,005, for example.
Two very different answers to this question…
Short youtube video explaining why tokenisation causes this bug. It’s an older video, so it talks about tokens as being whole-word rather than chunks of words, which is how most modern models work.
https://youtube.com/shorts/7pQrMAekdn4
The other persons explanation doesn’t acknowledge that emergent reasoning does kind-of exist in LLMs. That’s why theyre able to say how many 5’s are in a large number, despite never seeing that problem before. They dont ‘just’ repeat things they’ve been trained on, though they often do.
Of course, if that problem did exist significantly in the training data, it would be more likely to get it right. But you could say the same about any number of things an LLM doesn’t know.
Simply put, LLMs are great at forming sentences but can’t do math. Like, any math. If they get 60+21=81 right, it’s only going to be because it’s textually written somewhere in the training data that 60+21=81. However, it’s very unlikely for counting the number of Ts in colonialism to be in there, so it just hallucinates what it thinks is a correct response.
i seen without “thinking”, it tells you if there is 2.
google’s search ai does not have “thinking”
the looping thing i also seen before.We’re destroying the environment for this folks
Except for local LLMS.
Good to see so many people misunderstanding how local hosting works.
Running your own local LLM is no worse than running a graphically intensive game like cyberpunk 2077 or red dead redemption 2.
thats what i was thinking
No? If everyone who uses LLMs globally switched over to a local LLM (after buying the necessary hardware), that’d still be a crazy amount of energy usage, just less centralised.
More energy actually.
nah like using the current Gaming PC/Laptop you have, Like Intel CPU + intergrated graphics or smth.
I suppose, but that’s a very different class of model. I think a more important question might be whether people actually need LLMs at all.
whether people actually need LLMs at all.
this is personal preference ig.
No one in this post about Google is talking about local LLMs.
i was trying to say Local LLMS dont destroy the environment(cause its using the power of your pc instead)
Your computer uses more power when the GPU is “thinking” than when its idle, so there would still be environmental damage.
Training the models still uses a vast amount of resources
well atleast every prompt you ask it wont harm the environment
Megacorps don’t burn resources for the shake of it. They do it to train/run LLMS.
If all that running/training is done by the individual instead, the individual is going to be the one burning the resources.
In fact, it would probably be more resource intensive.
Since centralization and scale usually improves efficiency.
Most people don’t have computer hardware that was built with the sole purpose of training/running LLMs. LLM data centers do. Purpose-built hardware is more efficient than generic hardware.
If you are browsing Piefed you are probably using about 10-20% of your computer’s resources (if it is a computer capable of running a 4B model).
When you question the model and it pegs your system out, that is between 5 and 10 TIMES more resource utilization and power waste just to have a question answered that you could have taken the time to research, improve your own critical thinking skills, and learned something without changing your utilization at all.
Not counting the training debt.
i forgot about critical thinking, hehe.
but i hope my use of AI doesnt ruin it that much.
btw the best respones here.
“I’m not the one deforesting the amazon but I really love teak furniture, so I’M not the one hurting anybody by buying it”
Yeah, but Google search isn’t using local models.
sadly true
deleted by creator
There are so many better tools for this kind of thing.
like what?
plus i tend to use a search engine more often if i can find what i want.For counting letters in a word? That’s like a one line expression in Python or JavaScript (and other languages). JavaScript console is right there in your browser.
if javascript can do it,tell me how to do it?
const countOfT = (word) => word.split('').filter(i => i === 't').length countOfT('colonialism') 0 countOfT('this is an example sentence') 2There’s probably a more elegant way to do it.
nice to know that does not need AI ig
It took several tries but I got one that looped. Most of the time it gives the “there are 2” and puts random arrows.
This used to happen on chatgpt with “Is there a seahorse emoji”. Here’s a video explaining why this happens.

Wait the seahorse emoji is not real???
Whenever I see these, I try them out. Sometimes I can reproduce them, this one I can’t. However, I remain extremely skeptical and believe that whenever one of these screenshots goes around, someone at LLM Company hard codes a fix for that specific fuck up. Against how many of these hard fixes does each LLM answer get checked nowadays?!
I tried it, and got similiar shorter answers but not the exact same answer. Sometimes it ends up getting it right at the end after fumbling a lot, and sometimes it just fails completely.
Searching on Google directly sometimes doesn’t produce the AI Overview on stuff like these in my experience, but passing the search to Google from DDG with the bang (!g) almost always produces the AI Overview.
edit: I tried it again and it grew the ability of humor:
There are 2 't’s in the word colonialism. colt-a-ca-l-i-s-m (just kidding) C-o-l-o-n-i-a-l-i-s-m:
- t = 0 (If you were thinking of colonization, there is still only 1 ‘t’ in the word.)
Interestingly, on one of my attempts it used python to count the number of t’s and still ended up getting the “verbal” explanation wrong.
On the very long list of shitty things about AI is the fact that they are non-deterministic.
I was however able to get this fuckup on first try:

AI can make mistakes, so double-check responses
I’m sure it’s fine. After all, the AI triple-checked its answer!
Wow, you’re right. I got three different answers over five queries.
Right. Cause they aren’t answering the question. They are just determining the next most likely word.
I just tried this one and got:
There are 2 t’s in the word colonialism:
colonialism
They are located at the end of the word: the t and i at the end of the sequence.
They usually include some randomness in the responses which is why they don’t always respond the same way (and sometimes will even often but not always get the answer correct, or visa versa).
I am also trying from a non English speaking country, pretty sure that has an impact as well on behavior.
That could be, but I think a lot of the models are the same because they can speak many languages pretty well. I’ve had a lot of success with talking to models I normally prompt in English using other languages. But I have also seen Chinese appear unprompted in response to English queries from certain Chinese models a few times.
Oh yeah, an LLM itself doesn’t make that much of a difference. But Google does. Features and “features” often show up later on non English Google. The AI summary took a few months to appear on German google – even if you set your language to English.
I think that’s because they have to wait for more testing to make sure the model/feature is “safe” for that region and take into consideration the linguistic and cultural differences. I believe it’s mostly legal stuff they need to make sure they won’t be breaking laws in different countries and see if they would face backlash from authorities or the public. But I think it’s mostly the same model with the same data everywhere.
Here’s what I got:
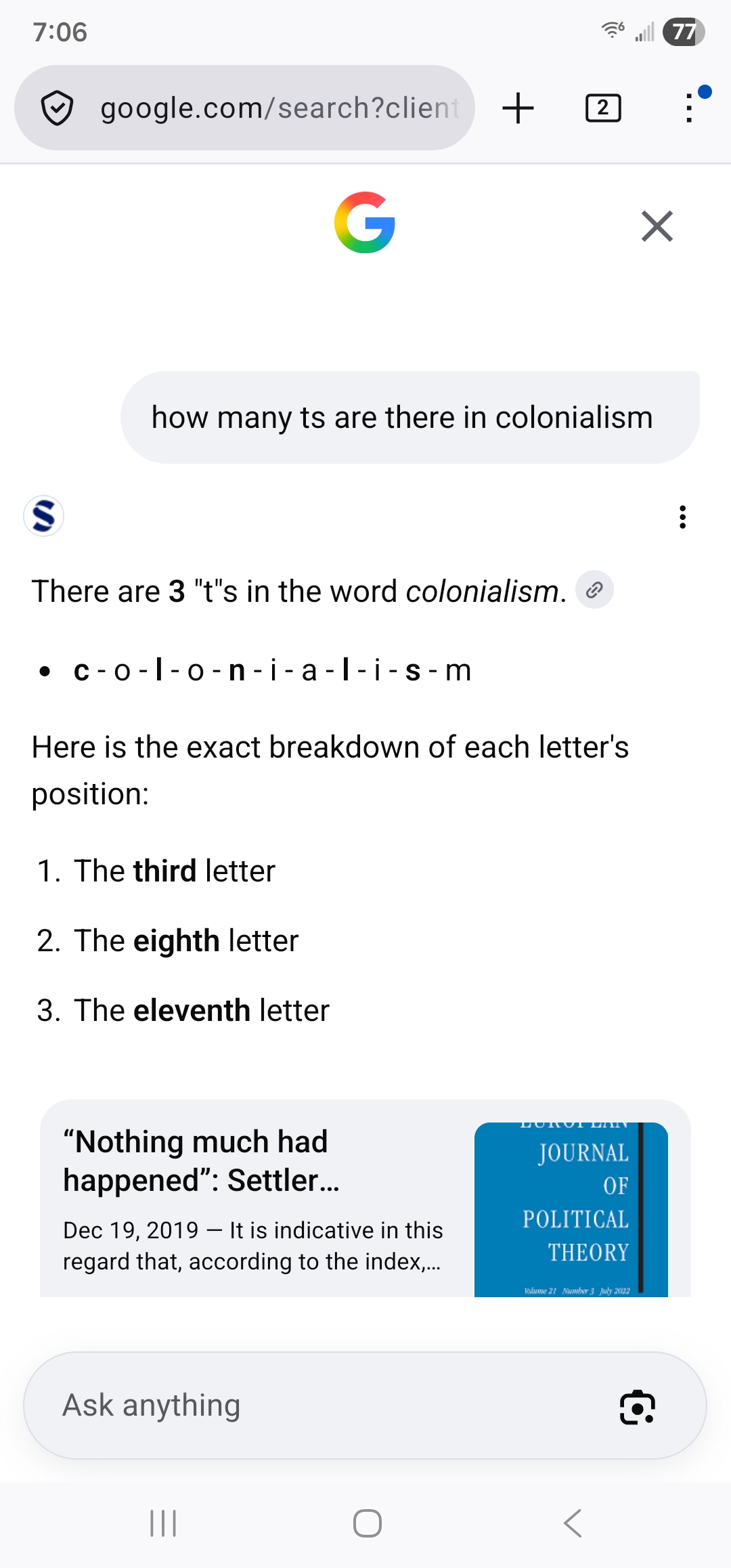
I can’t believe Google missed that third ‘t’ the first time around. So sloppy.

Try it with a thinking model + local model?






{kind=link}