Coder, Artist, Blogger (https://fungiverse.wordpress.com/, https://philpapers.org/archive/BINAKR.pdf, https://philpapers.org/rec/BINFPT-3, https://pinocchioverse.org/), former admin of https://diagonlemmy.social/, Programmer of MyceliumWebServer
- 9 Posts
- 7 Comments



 2·3 months ago
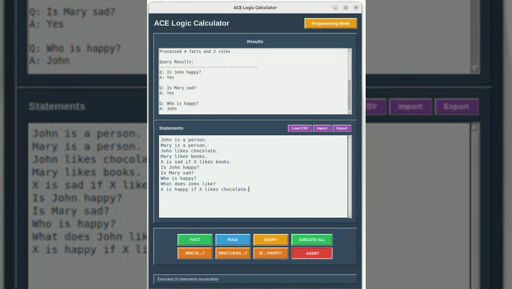
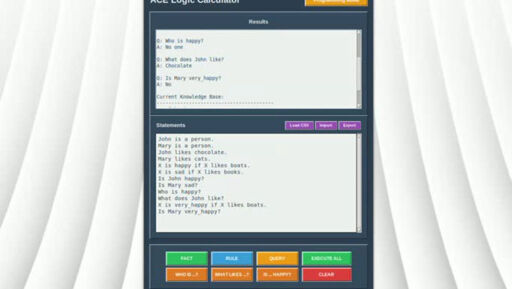
2·3 months agoI don’t know. Basically, if you already know what you want, maybe you only want to type down a couple of statements (maybe even from a template or a tutorial that you found online), modify some stuff and then hit enter. And maybe this modifying of language could be the “browsing” part of the browser.
If you look at it like this it would also be immediate and precise. You would only need to add very good code completion tools, e.g. when you click on a noun, you see all the attributes it has in your ontology. Much like in a IDE. There you also “browse” the space of all potential programs with the interface of language with code completion for keywords and defined concepts, which act like links in traditional browsers.
In contrast, the semantic web is like a open, global code base, where everybody can contribute to. And traditional browser could not successfully implement a language interface because the code base had no defined semantic, this would be possible for the semantic web. And using LLMs, it could be propagated into other web paradigms.
there are already text-based browsers like qutebrowser
hypercard
Awesome! Thanks for the references, didn’t know there were already some applications in this direction
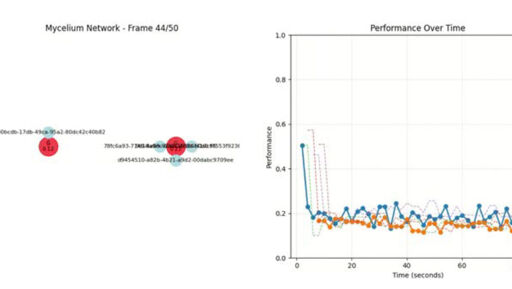
Cool. Well, the feedback until now was rather lukewarm. But that’s fine, I’m now going more in a P2P-direction. It would be cool to have a way for everybody to participate in the training of big AI models in case HuggingFace enshittifies
Yeah thats a good point. Also given that nodes could be fairly far apart from one another, this could become a serious problem.
Currently the nodes only recommend music (and are not really good at it tbh). But theoretically, it could be all kinds of machine learning problems (then again, there is the issue with scaling and quality of the training results).

I’s blurring the line in-between. It’s trying to set the interaction with the web on a lower level that is closer to the data. It’s like you are live-coding the website you want to use for a specific use-case. But then just call the high-level API-endpoints right away. Basically making the dev-tools and the dev-console of browsers the main way to interact with the web (which assumes a web that is build in a similar fashion).
Yeah, that’s true :(